David Wu on Building KataGo, the Limits of Go AI, and the Logic of Programming
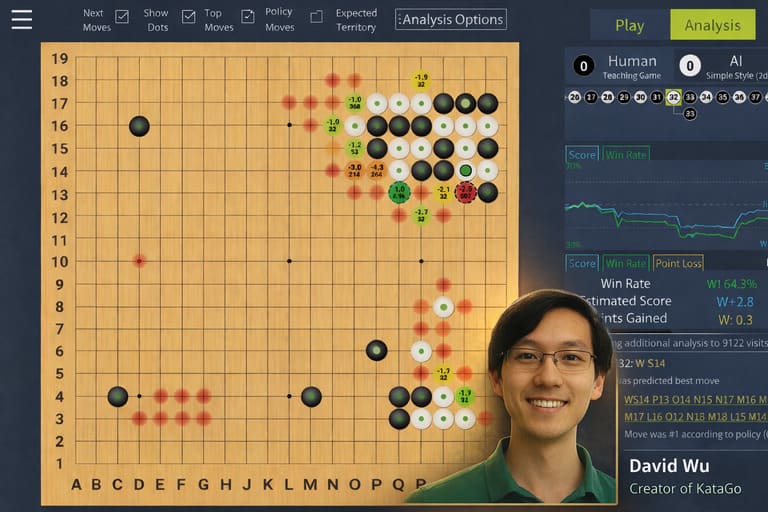

This article is an editorial adaptation of a conversation from the All Things Go podcast, featuring David Wu — the creator of KataGo.
In this conversation, Wu reflects on how he first discovered Go, how he taught himself programming, and how those paths gradually came together in the creation of KataGo. He also explains, in clear terms, how the system works, why it became more efficient than earlier AlphaZero-style approaches, and where Go AI still struggles — from circular groups to small-board analysis and the famous Igo Hatsuyōron 120 problem.
First Steps in Go and Programming
Travis:
How were you originally introduced to Go? What was the context, and what aspect kept you coming back to the game?
David Wu:
I honestly don’t remember that well when I was introduced to Go. It was sometime around middle school or high school. That was so long ago. I feel like it happened gradually: I knew about the game, maybe I picked up a book about it at some point, and then later, I think when I was back in Texas, I have a vague memory of going to the Austin Go Club and playing someone there.
I also vaguely remember one game from when I was a beginner. There was this pushing fight that went almost all the way across the board in a diagonal line because neither player wanted to give in. Then we started cutting each other, and the whole thing fell apart. So I don’t remember the beginning very clearly, but I started playing around then and kept playing on and off into college. Around middle school and high school was also when I started getting into computer programming and coding, so the two things developed a little hand in hand.
Travis:
When you started coding and working with algorithms, were games like Go a natural place for you to explore your interest in artificial intelligence?
David Wu:
I experimented with a lot of different things. I’ve been fairly self-taught when it comes to coding. My dad introduced me to programming when I was pretty young. I didn’t really do much with it at first, but I knew about it and had done some basic things. Then I realized that, just from that background knowledge and from being around computers, by the time I took a computer science course in high school, I already knew everything they were teaching in the first semester. The teacher more or less let me do my own thing.
By the time the next course came around the following year, I had already taught myself everything they were going to cover there too. So I kept proceeding that way — writing different programs, doing things like a fluid simulation, and various other random projects. One of the things that drew me in fairly early was AI, especially bots for games, because I found the algorithms really interesting.
But I mostly stuck to niche games. I did not touch Go at all. There was a game called Slime Wars or Attacks that I wrote a simple bot for, and things like that. I wanted to explore interesting problems I didn’t see other people working on very much. So I stayed far away from writing a chess bot, and I stayed away from computer Go as well, because even back then there was already a lot of work going on there.
Travis:
What was the reasoning behind that? Was it because so much work had already been done on the chess side of things?
David Wu:
Yeah. I didn’t want to write the n-plus-first chess bot. I wanted to do something I hadn’t seen before. Even if it wasn’t very good, I still wanted it to be at least a little interesting and unique.
Go and Coding Use Different Kinds of Thinking
Travis:
As recently as a few years ago, you were a dan-level Go player. How do you feel your skills as a researcher and coder lend themselves to excelling at the game?
David Wu:
I almost think they don’t. It’s a very different skill set. When I write code, or work on algorithms, I often approach it almost like I’m writing a proof. I’m trying to prove to myself that the code works at the same time I’m writing it.
Programming requires a lot of precision. You’re looping over data, processing it in a certain way, and constantly tracking conditions that have to be true. If something might be empty, you need to handle that case. If you might divide by zero, you need to check for zero first. You’re always keeping track of the state of the code and the state of the algorithm, and writing everything in a way that depends on those conditions being correct. There’s a lot of mental bookkeeping in that.
The way I approach Go, and a lot of other strategic games, is much more intuitive. Snap pattern recognition is really the main driver. You recognize shapes and situations, and of course there’s some reading on top of that, but a lot of it comes down to very fuzzy judgment calls. It feels like it exercises a different part of the brain.
That’s also part of what I enjoy about it. You get the same kind of thing in some board games or strategy video games, where it’s impossible to read out every consequence. You rely on experience and make fine judgment calls about what seems best in the position. For me, Go is much closer to that kind of thinking than it is to the way I write code.
How KataGo Works
Travis:
Could you give us a high-level overview of how KataGo works — using training data, neural networks, and search — and how it became such a powerful tool for improving at Go and reviewing moves?
David Wu:
Sure. It works in broadly the same way people may have heard explained in things like the AlphaGo documentary. KataGo is based on, and extends, the kind of technology developed by DeepMind for systems like AlphaZero, along with some related ideas from other work around that time.
At the center of it is a neural network. You train it in a certain way, and it takes a board position as input and produces two main outputs. One is its best guesses for the most plausible next moves. The other is how likely it thinks each player is to win from that position.
Given those two things, you can then build an algorithm on top of the neural net that actually plays better than the neural net could by itself. In practice, that means doing reading on top of the network. The neural net suggests promising moves, you play those moves out, generate possible follow-up positions, and then ask the neural net how good those positions are, how likely they are to lead to a win, and what the best responses would be from there.
You keep building out the game tree that way. In effect, you analyze the position by trying possible moves and checking whether they really lead to something favorable, or whether the neural net may have been misjudging things at first. After that analysis, you end up with a better estimate of what the best moves are and a better estimate of who is likely to win.
Then you play a large number of games against yourself, and in every position you do that same search. So now you have a player that is stronger than the raw neural net, because it is the neural net plus all this additional reading. That produces data showing how a stronger player would actually play. You then train the neural net to predict that stronger play.
So the neural net improves by learning from a version of the player that is already stronger than it is on its own. But that stronger player exists only because the search is built on top of the neural net in the first place. That creates a feedback loop: neural net, search, self-play, retraining, and then back again. Over time, that loop makes the bot stronger and stronger.
Why the Name “KataGo”
Travis:
As we were getting ready for this conversation, I was doing some reading about you and KataGo, and at one point I had to take my five-year-old son to karate class. I was sitting there in the back, and at the end they were telling the kids to practice their kata. I looked down at the name KataGo and thought, “Wait a second.” Could you give us a quick explanation of how you came up with the name?
David Wu:
Honestly, there wasn’t that much thought behind it. It basically is what you just mentioned. As I understand it — and my knowledge here isn’t especially deep — kata is a Japanese loanword that refers to a martial arts form: a sequence of movements practiced alone, without an opponent. You go through those motions to improve the quality of your form over time.
And when I think about what the Go bot is doing during self-play, it doesn’t really have an opponent other than itself. It is on its own, exploring the game and trying to get better. That reminded me of the idea of kata, so I named it KataGo as a reference to that — a system learning by itself and polishing its own sense of shape, its own sense of which moves are good or bad, and how to play, all on its own.
Why KataGo Became More Efficient Than the Original AlphaZero Approach
Travis:
You mentioned AlphaGo and DeepMind. In an earlier interview, you said AlphaGo was at least part of the inspiration, but my understanding is that you approached the problem differently. DeepMind had enormous funding and computational resources, while you were able to train a system much more efficiently and with far fewer resources. How did that work?
David Wu:
That was part of why I chose that moment to get into it. When DeepMind was doing its original research on AlphaGo and AlphaZero, they made a deliberate point of not trying game-specific improvements and not using more complex algorithms. They wanted to keep things as vanilla as possible. The goal was to show that this new kind of system was so effective at learning that, even without extra optimizations on top, it could still beat the previous generation of systems.
For a while, people took that to mean maybe it was actually best not to add anything on top. But I don’t think that turned out to be true. Precisely because DeepMind kept the system so vanilla, once you started adding a little more complexity and doing things in a slightly more clever way, there turned out to be a lot of room for improvement. I’m sure the DeepMind researchers knew many of those optimizations were possible, but they deliberately avoided them in order to keep the research clean, simple, and easy to analyze.
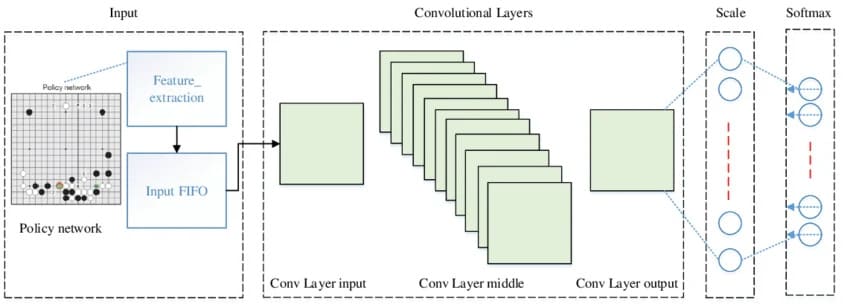
So after AlphaZero, the door was wide open. There was all this low-hanging fruit that had specifically been left unpicked. A lot of people, including enthusiasts working on things like Leela Chess Zero, found the same thing: immediately after AlphaZero, there were many easy improvements available. That made it a very fun area to experiment in, because instead of new ideas failing most of the time, a lot of them actually worked. And that is a big part of why KataGo was able to gain so much efficiency. Once you start optimizing for the fact that you are actually playing Go, there are many straightforward wins in both the neural net and the training algorithm.
Travis:
And is that partly because you’re a Go player yourself — a dan-level player — so you have some intuition for what actually matters in the game?
David Wu:
Some of it, yes. A little of it is having intuition for the kinds of things that matter specifically in Go. One example is that the original AlphaZero neural net architecture didn’t really have any component that could see the whole board at once. Every layer was a convolutional layer, which means it processed the board in a very local way: the values at one layer depended only on nearby points from the previous layer. So it took many layers for information to travel across the board and back.
One of the simplest ideas, if you understand Go, is that it is often useful to see the whole board when making a local decision. There may be a ko in the opposite corner, and you need to know whether there are ko threats elsewhere. Or you may need a better sense of who is ahead or behind so you can choose a more aggressive or more conservative direction. So one of the first things I tried was adding simple mechanisms that let the neural net aggregate information from the whole board within a single layer. Not surprisingly, that helped a lot. The network became much stronger once it had that ability.
Some of the improvements I tried were more general and not really Go-specific. One example is the way training data is balanced. If you run the AlphaZero setup in a fairly vanilla way on Go, you get much more information about which moves are good or bad than you do about who is winning. Over the course of a game, you get a lot of feedback on tactical success or failure — whether a move worked, whether a group lived or died — but only one final signal about who actually won the game. That means the part of the neural net that predicts the winner learns relatively slowly and with a lot of noise, while the part that learns move quality improves faster.
So there are things you can do in the training setup to rebalance that. You can sample fewer turns for move training, play more games overall with the same compute, and effectively shift more data toward the part of the network that is learning too slowly. In other words, you give less data to the part that is already learning quickly and more to the part that needs the help. That makes the overall learning process more effective.
The Circular Group Problem: Where Bots Still Misjudge Go
Travis:
As we were preparing for this conversation, there were two or three major areas that kept coming up in our email exchange and in the research around KataGo. One of the most interesting was this adversarial, circular situation that people found. Maybe we could start there.
David Wu:
Sure. There was some work by a research group that did a very interesting combination of analysis and training, and they found that KataGo — along with pretty much every other bot people were able to test — had a weakness in positions where a group wraps back around on itself in a loop. In those cases, the surrounded group may actually be alive, or at least have enough eye space and enough liberties to win a capturing race against the surrounding group, but the bot misjudges the position.
People are not entirely sure why neural nets tend to make this kind of mistake by default. More recent experiments have shown that you can reduce the problem in the bulk of cases, but even then these circular-group positions still expose flaws.
Travis:
Was part of the issue simply training data — that there just were not many games where this kind of thing happened — or is it more complicated than that?
David Wu:
It is partly training data, and partly the fact that groups that loop back around on themselves are just different. There is a heuristic that usually works for deciding whether an eye is real or false. Roughly speaking, if the opponent controls at least two of the four corner points around the eye, it is false; if they control fewer than two, it is real. That heuristic works often enough to be useful, but it is not a perfect rule, and it breaks down for a group in a loop.
There is a shape called the two-headed dragon where it looks as though the group has two false eyes, but in fact those eyes function as real ones and the group survives. Humans can get tricked by that too at first. You sometimes see people ask why a move should be played there, or why the group is not dead when it seems like it ought to be. So it is a little unintuitive even for humans.
But humans can usually pick up the concept fairly quickly once it is explained. A neural net does not seem to adapt in that way. It is more restricted by what is in its training data. Cyclic groups, two-headed dragons, and related shapes are probably not completely absent from training, but they are very rare. So the network has not fit those cases very well. It ends up extrapolating from more ordinary group behavior, and in these unusual positions it extrapolates incorrectly.
That is really the heart of the problem: certain heuristics work for ordinary groups, then fail on cyclic shapes, and the neural net leans on patterns that are mostly right but wrong in exactly these rare corner cases.
Why This Problem Is Still Not Fundamentally Solved
Travis:
Where are things now? That research project came out, I think, a year or two ago. Has the situation improved? Has KataGo been given more training data to start addressing the issue?
David Wu:
From a fundamental research perspective, the issue is still unsolved. No one really knows how to make neural nets robust to this kind of position in a truly reliable way. What does work, at least partially, is to add more examples by hand — generating more positions with cyclic groups and similar shapes and putting them into the training data. That mostly works okay. The vast majority of positions that KataGo used to evaluate incorrectly are now judged correctly, because it has seen many more examples that reinforce the right evaluation.
But that still does not solve the deeper problem. There are just too many corner cases. Even if you put cyclic groups aside for a moment and think only about capturing races in Go, the number of possibilities becomes enormous. You have groups with very different numbers of liberties, shared liberties versus outside liberties, approach liberties, small eyes and big eyes, heuristics like “big eye beats small eye” that are useful but not always correct, different eye sizes counting for different numbers of liberties, ko fights between groups, and not just two groups but sometimes three or four groups interacting at once. Every variation creates another layer of complexity.
So it becomes a combinatorial explosion. Even if you generate a great deal of training data for cyclic groups, you can make the neural net handle most cases well, but there will still be some specific configuration where the right combination of factors appears, the cycle is large enough, and the network still fails. That is why the problem remains open in a deeper sense.
Humans seem to deal with this differently. A person can often understand the key concept after seeing only a few examples. Neural nets do not appear to learn that way. They seem to rely much more on brute force — seeing enough examples, across enough permutations, that they become mostly correct. But “mostly correct” still leaves those needle-in-a-haystack weaknesses.
Small Boards: 7×7, 8×8, 9×9
Travis:
Another topic that came up was your work on small boards — trying to understand optimal play, and even things like what the optimal komi should be. Could you give a high-level overview of that project and what you found?
David Wu:
People have been curious about optimal play on small boards for a long time, even before neural nets. As far as rigorously solved boards go, I believe the largest size that has actually been fully proven is 5×5 — or possibly 5×6. And even on boards that small, once solvers became available, they found some lines that were fairly unintuitive. On 5×5, for example, normal play starts in the center and Black owns the whole board, but if you deliberately make Black’s opening suboptimal and then ask what the best continuation is from there, some of the optimal lines turn out not to be obvious at all.
A few years ago, I got curious about what would happen if I threw KataGo at the small boards. So I had it analyze a large number of positions on 7×7 and 8×8. I spent at least a couple of months of GPU compute just expanding the tree and analyzing lines.
One of the interesting things on 7×7 was that there had already been many human attempts to solve the board, going back at least to the 1990s. And KataGo did confirm a lot of those human lines. But it also found a few places where Black, under Japanese rules, seems able to do better than people had thought. There is one particular key move several moves deep into one variation that is fairly surprising if you have not seen it before, and it lets Black do one point better. There were also a number of side variations where KataGo found very surprising moves that seem to hold up under analysis, sometimes improving the result by a point or two.
So part of the appeal was simply intellectual curiosity: take a strong bot, point it at these smaller versions of the game, and see what it produces. I ran those analyses for a few months and posted the results.
After that, I tried the same kind of thing on 9×9, because 9×9 is a board size people actually play. But 9×9 is already far too complicated for anything like a full solution. Not even close. Even on 7×7, what you get is not a mathematically rigorous proof — it is just a very strong bot’s probably mostly accurate guess about what optimal play looks like.
That is the important distinction with small boards: the very smallest ones can be proved, but once you move up to 7×7, 8×8, and especially 9×9, you are no longer talking about a strict solution. You are talking about increasingly strong analysis, increasingly good guesses, and occasionally some very surprising improvements — but not proof.
Why 9×9 Is Still Far from Being Solved
Travis:
What would it actually take to prove something like that rigorously? Is it mainly a matter of throwing more resources at the problem, or is it beyond that?
David Wu:
At that point, you really are talking about brute-force compute. And for 7×7, getting all the way to a mathematically rigorous proof is probably beyond current abilities. The computer to do it simply does not exist right now. Even 6×6 is not rigorously proven. 5×5 is, but once the board gets larger, the complexity of proving optimal play rises exponentially.
So for 9×9, the only realistic thing you can hope for is something like a reasonable opening book — a strong guide to the probably good opening lines. That is very different from solving the game.
I did try throwing KataGo at 9×9 directly, but it was not good enough for what I wanted. It kept changing its mind on different lines, finding refutations to its own play, and producing evaluations that still looked questionable once you explored them interactively with KataGo or with other bots.
So I ended up spending a few months training a neural net specifically for 9×9. I took one of KataGo’s current networks at the time and fine-tuned it for a few more months only on 9×9, with a much wider variety of positions, including many of the positions it had been mis-evaluating before. Then I used that specialized network to build what became the current 9×9 opening book.
That training made it a lot better, but even then there were still many lines with questionable evaluations. If you browse the 9×9 book, it is very easy to enter side variations where the win rate is something like 70 percent. And that alone tells you how far it still is from being solved. If the position were actually solved, the evaluation would not look like that. It would be exact: either perfectly balanced, or a definite win or loss. A 70 percent evaluation means the system is still unsure.
Travis:
So is there at least some sense in which this resembles chess opening theory — not because the games are the same, but because on 9×9 you can at least confirm some opening ideas even if the full game is nowhere near solved?
David Wu:
You cannot really say anything for sure on 9×9. My guess is that top bots, with practical amounts of compute, a very strong GPU, neural nets trained specifically for 9×9, and millions of playouts per move, probably do play optimally most of the time. If some all-knowing judge looked back at those games, the answer would probably be that there were no real mistakes in many of them. But that is still a very long way from proving it. Strong practical play and mathematical certainty are two very different things.
Igo Hatsuyōron 120 and What Happened When KataGo Was Trained on It
Travis:
My understanding is that there is this problem collection called Igo Hatsuyōron — a book of Go problems or tsumego dating back to the early 1700s, from the height of the Japanese Go schools. One of the 183 problems in it, problem 120, has drawn analysis for hundreds of years. The original answer seems to have been known only to a few people, and the record of it may have been lost. Could you give us some backdrop on the problem itself, and on what happened when you brought KataGo into the picture?
David Wu:
Yes. This is a very famous problem. It is a whole-board problem built around an extremely unusual capturing-race position. One of the major elements in that position is what’s called a hanezeki, where one side has a gigantic string of stones — more than a dozen — sitting in atari, and those stones are also cutting stones. Yet the other side cannot simply capture them, because doing so at the wrong moment makes the overall capturing race collapse in an unfavorable way.
So both sides have to keep playing it out. Various fights develop, the variations become enormously complicated, and eventually one side or the other may be forced to capture — but only at the right time. There has been a great deal of amateur and professional analysis of this problem over many years, and new moves had already been discovered long before I got involved.
When I was working on KataGo, I came across this unsolved problem and wondered what would happen if I trained specifically on it. I had not heard of anyone else trying that, and I was very curious. The idea was: just as you can train a bot from the empty Go board and have it learn to play Go, what happens if you train it from this exact starting position and make the entire game be, “Start from here and play as well as you can”?
That special training was necessary because if you take a Go bot trained only for normal play and throw it at this whole-board problem, it is basically hopeless. The hanezeki situation is so rare in ordinary games that the bot mis-evaluates it badly. In particular, you have this huge group in atari that cannot actually be captured immediately, even though under normal circumstances a group like that obviously should be capturable. Together with the surrounding capturing race, it becomes a very hard position to judge.
So I trained a bot on this position. At first I trained it for about one week. During that week I kept watching how its play changed over the course of training, and about halfway through it started producing some interesting new moves that I had not seen in other analyses of the problem. For the most part it followed the existing human analysis, but there were a few key deviations. I posted those tentative findings, and from there the work continued.
Human Analysis and AI Analysis Together
Travis:
So after that initial training run, the project didn’t stop there. My understanding is that other researchers and enthusiasts kept pushing the analysis further.
David Wu:
Right. What I did was really just the initial one-week training run and the first set of results. After that, most of the work was done by a few dedicated researchers and volunteers who kept training KataGo on the problem for months and also put a great deal of human effort into understanding what the new results actually meant.
There is one particularly dedicated enthusiast I stayed in contact with, helping them run KataGo and analyze things, and over time they worked out much more of the new analysis. So the current state of the problem is fairly different from what people thought five or ten years ago, both in terms of who wins and by how much.
Travis:
And as of around February 2022, it sounded like the problem was at least potentially solved — after a total of about eleven months of KataGo training, with a main line of 205 moves ending in White ahead by one point.
David Wu:
I haven’t kept fully up to date with every later development, and I would really describe that as their work, not mine. The part I contributed was the initial week of training and those first results. Since then, there have been further optimizations, refinements, and new side variations discovered.
Travis:
So in a sense, KataGo helped confirm some of the strongest human ideas, but it also found something genuinely new.
David Wu:
Yes. After those first new moves were discovered, human analysis was able to take things a little further, using KataGo as a tool to test the ideas and try to poke holes in them. It’s an interesting case where, at least for that stretch, combined human and AI analysis was a little better than either one alone.
Playing Go, Maintaining KataGo, and What David Is Proud Of
Travis:
Lightning round: do you still play Go for fun? And if so, what kind of games do you prefer?
David Wu:
Not very much. I haven’t played seriously for a long time. These days I mostly maintain KataGo and have moved on to other things, though I might still be up for an occasional game with a friend.
Travis:
When you did play more, what time settings did you usually like?
David Wu:
Mostly relatively slow games. I get a lot worse at blitz — more than most people, I think. Everyone gets worse in blitz, of course, but I really rely on having time to settle my feeling for a position, read out some possibilities, and figure things out.
Travis:
How much time does maintaining KataGo take on a regular basis?
David Wu:
It varies a lot. On average, most weeks it is probably something like one or two hours. But if I’m working on a new feature, it can be five or ten hours. And in the really busy periods — especially during the early development, when I was getting the distributed setup in place — there were stretches of a few weeks where it was more like thirty or forty hours in a week, on top of a full-time job.
Travis:
If you had to pick one achievement with KataGo that you’re most proud of, what would it be?
David Wu:
I’m not entirely sure, but if I had to choose, it would probably be getting it running in distributed fashion. Originally, KataGo didn’t have a way for people to contribute directly. So building the infrastructure that allowed others to take part — and then seeing that people actually felt it was worthwhile to donate their computing power — was a moment that felt really good.
Travis:
And if you could start over from the beginning, knowing what you know now, what would you change about KataGo’s development or use?
David Wu:
I’m not sure I have a neat answer to that. I think most of what I would want to do differently is not really about starting over. It’s more about having the time, ability, and resources to test more things properly. There are still many open questions — what the optimal network size is, which run parameters are better overall — and with the amount of compute available, you often only get to do one run. It’s hard to test lots of alternatives. So more than wishing I had made some specific different choice early on, I mostly wish there had been more room to experiment and verify things.





Оставить комментарий